データリシェイプ - 原理
データリシェイプ
VSeed は、データ可視化のハードルをさらに下げるために、汎用的なディメンションリシェイプ方法を提案します。
データリシェイプとは、データをある構造化形式から別の構造化形式へ変換するプロセスです。核心は、データの完全性を保ちながら、行、列、インデックス、階層などのデータの組織方法を変え、異なる分析や処理ニーズに適応させることです。
ディメンションリシェイプ
Python と R には、すでにディメンションリシェイプをサポートするツールがあります。
- Python Pandas は
pivotとmeltによるデータリシェイプを提供します - R tidyverse は
pivot_longerとpivot_widerによるデータリシェイプを提供します
昇次元と降次元
昇次元と降次元は精神的には圏論の考え方(対象と射、同型)に沿っていますが、実装上は厳密に圏論に従っているわけではありません。
特に強調すべき点:
- 昇次元では、存在しない「指標名」と「指標値」の情報を「無から」作成します
- 降次元では、データ内に存在する「指標名」と「指標値」の情報を「削除」します
昇次元はデータを完全に変換できますが、ディメンション列名に空値が出ることがあるため、追加情報による補完をサポートします。 降次元は情報内容を失うため、真の意味での同型変換を実現するには追加の変換情報を保存する必要があります。そうしなければ、情報は必ず失われます。
グループ化された昇次元と降次元
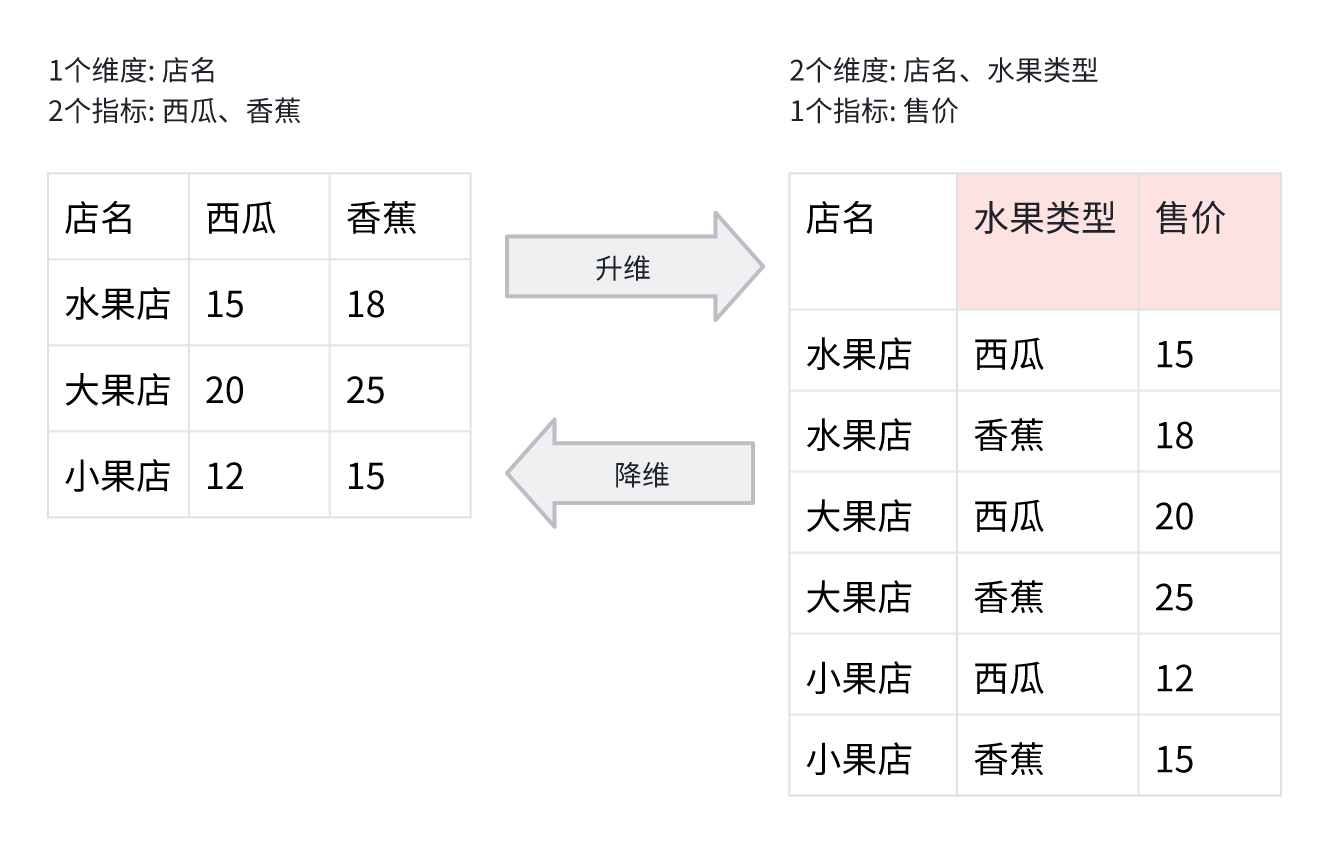
通常の昇次元と降次元と同様に、情報追加または情報損失の場面があります。さらに、グループの導入により、より多くの空データが発生します。
作用と意味:
- 指標グループ化: グループ化された昇次元により、明細データをすばやく処理できます
- 複数グループクエリ: 複数の SQL によって複数の明細データを簡単に取得し、グループ化された降次元によって 1 つのデータに結合できます

規則の導出
昇次元


:::tip
- 複数指標の昇次元では、指標数が 1 になります。1 個の指標を昇次元しても、指標はやはり 1 個です。
- 複数ディメンションの昇次元では、ディメンションが 1 つ増えます。0 個のディメンションでも 1 つ増えます。
- 0 個のディメンションと 1 個の指標は、繰り返し昇次元することで任意個のディメンションと 1 個の指標を得られます(つまり、1 個の指標でも棒グラフを描けます) :::
降次元

:::tip
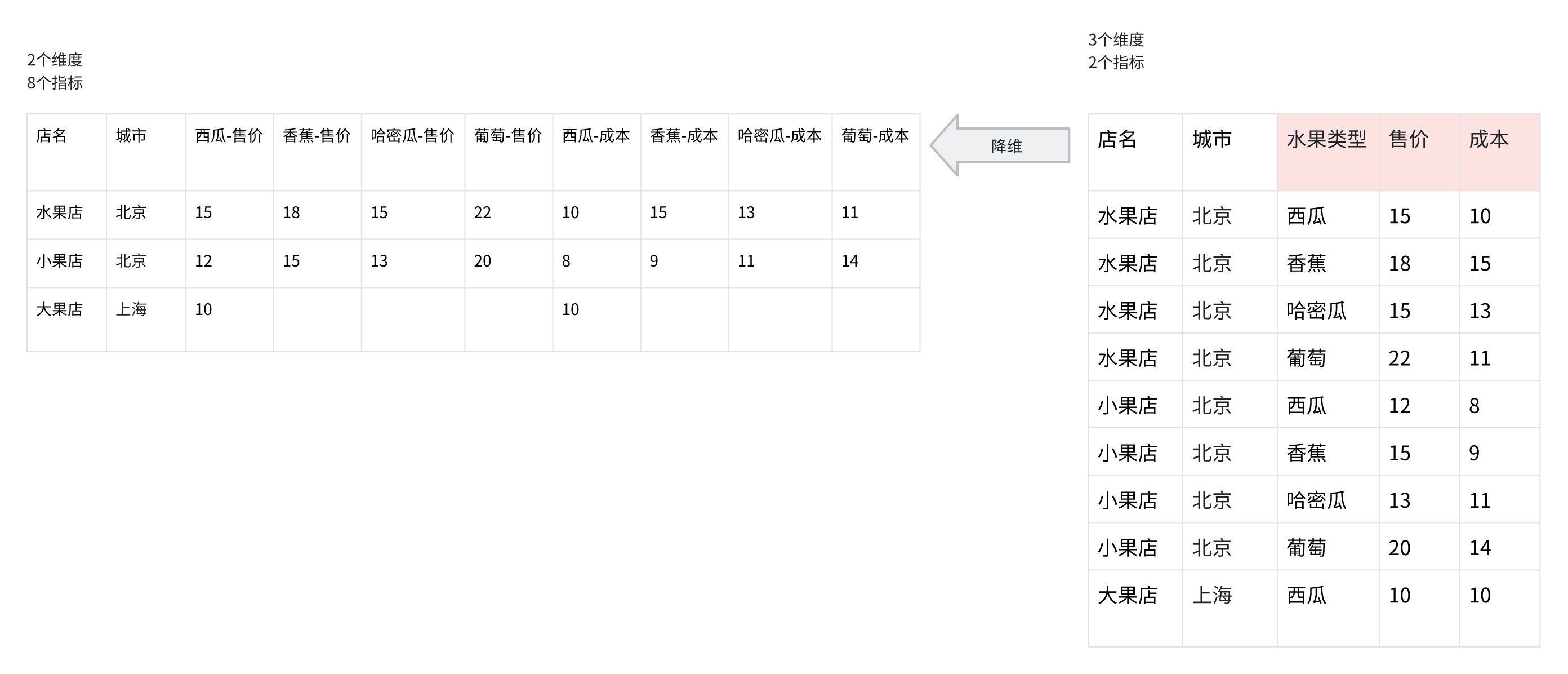
- 複数指標の降次元では、ディメンション値と指標がデカルト積を形成し、新しい指標になります
- 複数ディメンションの降次元では、複数のディメンション値がデカルト積を形成し、新しいディメンションになります :::
例
0 個のディメンション、1 個の指標

0 個のディメンション、3 個の指標

1 個のディメンション、1 個の指標
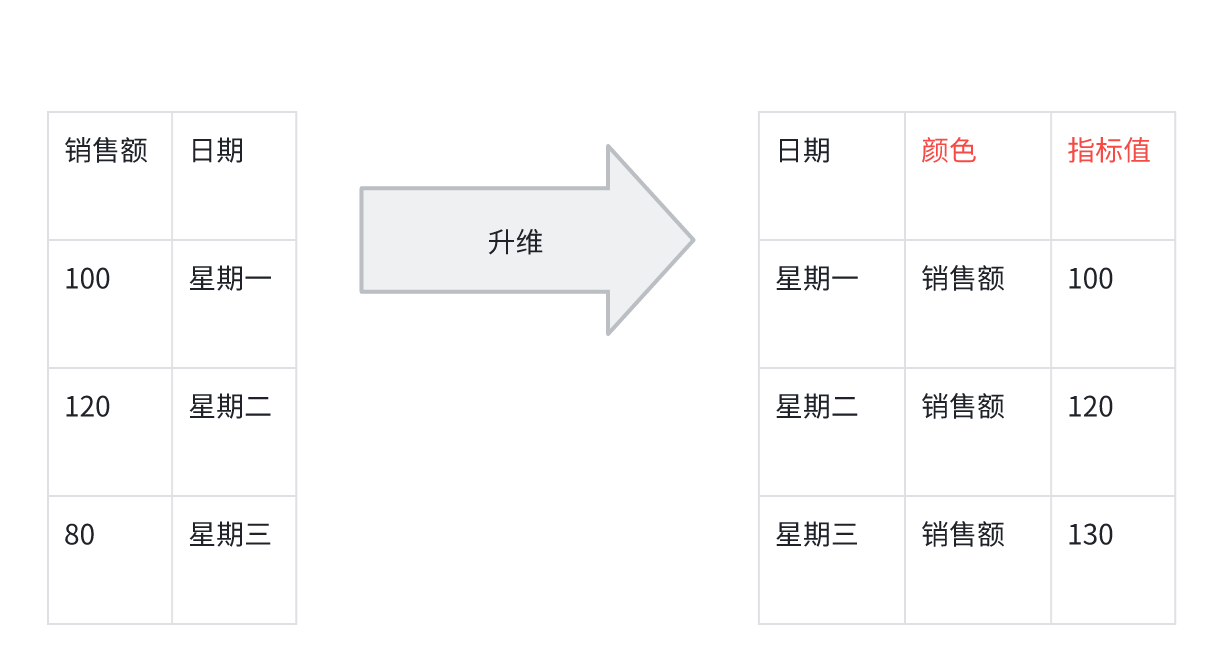
1 個のディメンション、2 個の指標

2 個のディメンション、1 個の指標

2 個のディメンション、2 個の指標
