데이터 재구성 - 원리
데이터 재구성
VSeed는 데이터 시각화의 진입 장벽을 더 낮추기 위해 범용적인 dimension 재구성 방법을 제안합니다.
데이터 재구성은 데이터를 한 구조화된 형태에서 다른 구조화된 형태로 변환하는 과정입니다. 핵심은 데이터의 무결성을 유지하면서 행, 열, 인덱스, 계층 등 데이터의 조직 방식을 바꿔 서로 다른 분석 또는 처리 요구에 맞추는 것입니다.
Dimension 재구성
Python과 R에는 이미 dimension 재구성을 지원하는 도구가 있습니다:
- Python Pandas는 데이터 재구성을 위해
pivot과melt를 제공합니다 - R tidyverse는 데이터 재구성을 위해
pivot_longer와pivot_wider를 제공합니다
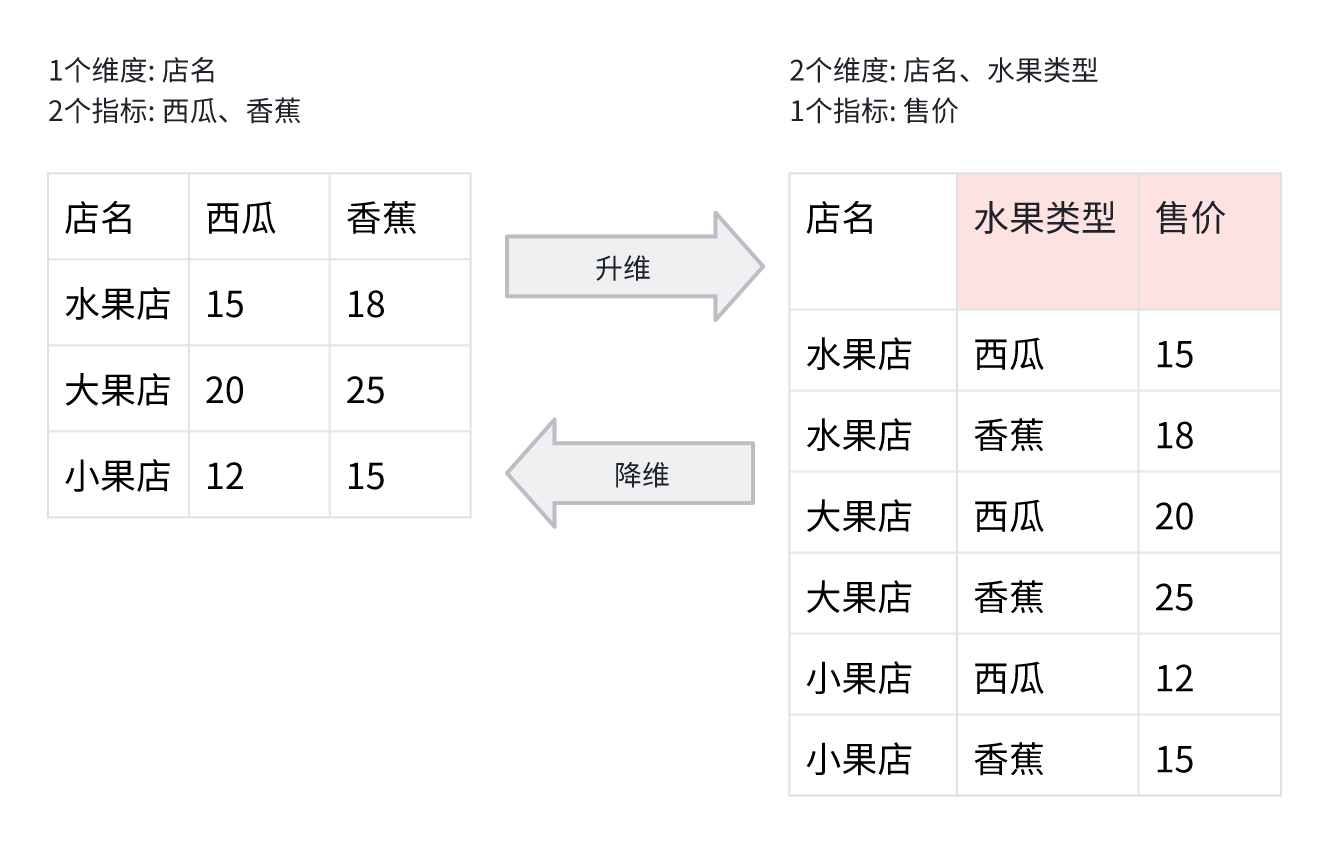
차원 확장과 차원 축소
차원 확장과 차원 축소는 정신적으로 범주론의 사고(대상과 사상, 동형)에 부합하지만, 구현상 엄격하게 범주론을 따르지는 않습니다.
특별히 강조할 점:
- 차원 확장 시 존재하지 않는 "measure name"과 "measure value" 정보를 "무에서" 생성합니다
- 차원 축소 시 데이터에 존재하는 "measure name"과 "measure value" 정보를 "제거"합니다
차원 확장은 데이터를 완전하게 변환할 수 있지만, dimension 열 이름에 빈 값이 생길 수 있으므로 추가 정보 보완을 지원합니다. 차원 축소는 정보 내용을 잃기 때문에, 진정한 의미의 동형 변환을 달성하려면 추가 변환 정보를 저장해야 합니다. 그렇지 않으면 정보는 반드시 손실됩니다.
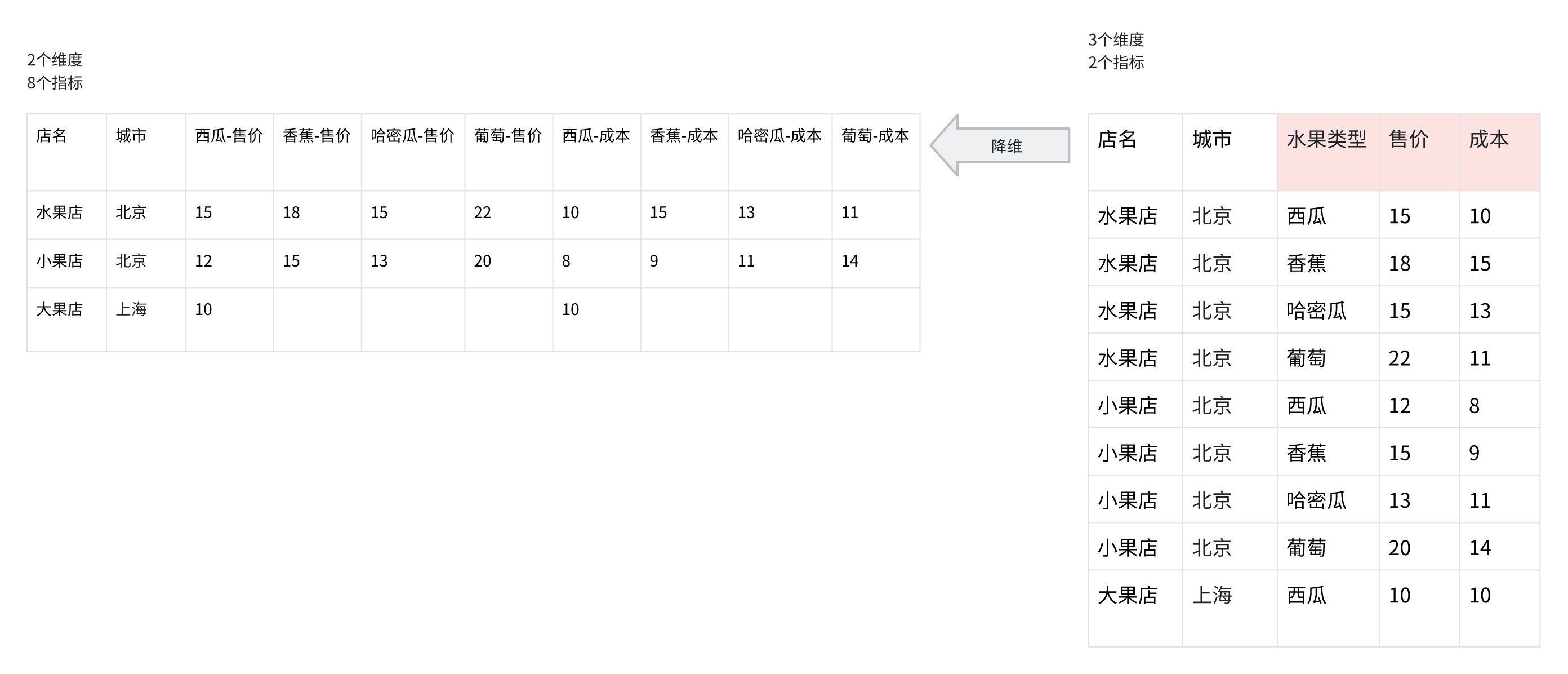
그룹화된 차원 확장과 차원 축소
일반적인 차원 확장과 차원 축소처럼 정보가 추가되거나 손실되는 유사한 상황이 있습니다. 또한 그룹이 도입되면서 더 많은 빈 데이터가 생성됩니다.
작용 의미:
- measure 그룹화: 그룹화된 차원 확장을 통해 상세 데이터를 쉽게 처리합니다
- 다중 그룹 쿼리: 여러 SQL로 여러 상세 데이터를 쉽게 가져올 수 있으며, 그룹화된 차원 축소 방식으로 하나의 데이터로 병합할 수 있습니다

규칙 도출
차원 확장


:::tip
- 여러 measure를 차원 확장하면 measure 수가 1이 됩니다. 1개 measure를 차원 확장해도 measure는 여전히 1개입니다.
- 여러 dimension을 차원 확장하면 dimension이 하나 더 늘어납니다. 0개 dimension도 1개가 됩니다.
- 0개 dimension, 1개 measure는 반복적으로 차원 확장하여 임의 개수의 dimension과 1개 measure를 얻을 수 있습니다. 따라서 1개 measure로도 막대그래프를 그릴 수 있습니다. :::
차원 축소

:::tip
- 여러 measure를 차원 축소하면 dimension 값과 measure가 데카르트 곱을 이루어 새로운 measure가 됩니다
- 여러 dimension을 차원 축소하면 여러 dimension 값이 데카르트 곱을 이루어 새로운 dimension이 됩니다 :::
예시
0개 dimension, 1개 measure

0개 dimension, 3개 measure

1개 dimension, 1개 measure
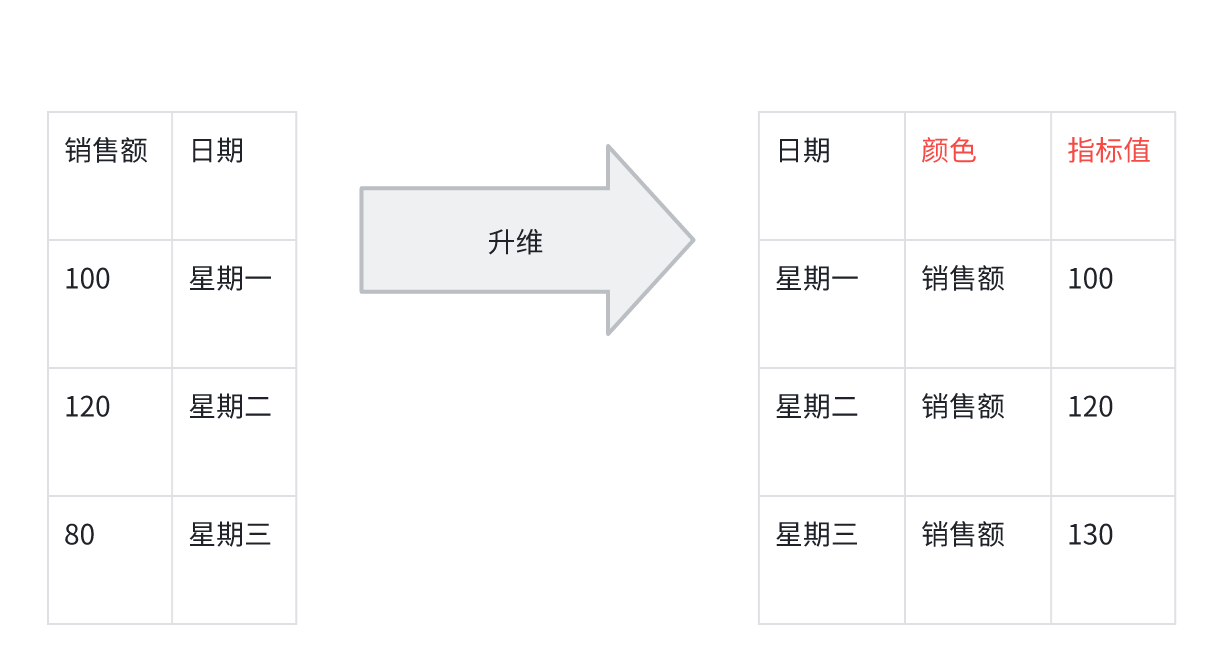
1개 dimension, 2개 measure

2개 dimension, 1개 measure

2개 dimension, 2개 measure
