Remodelage des données - Principes
VSeed propose une méthode universelle de remodelage des dimensions afin d'abaisser davantage le seuil d'accès à la visualisation des données.
Le remodelage des données consiste à convertir les données d'une forme structurée vers une autre. L'essentiel est de modifier l'organisation des données, comme les lignes, colonnes, index et hiérarchies, afin de répondre à différents besoins d'analyse ou de traitement tout en conservant l'intégrité des données.
Remodelage des dimensions
Python et R disposent déjà d'outils prenant en charge le remodelage des dimensions :
- Python Pandas fournit
pivotetmeltpour le remodelage des données - R tidyverse fournit
pivot_longeretpivot_widerpour le remodelage des données
Augmentation et réduction des dimensions
L'augmentation et la réduction des dimensions rejoignent, dans l'esprit, la théorie des catégories (objets, morphismes et isomorphismes), mais leur implémentation ne suit pas strictement cette théorie.
Points importants :
- Lors de l'augmentation de dimension, les informations « nom de mesure » et « valeur de mesure » inexistantes sont créées « à partir de rien »
- Lors de la réduction de dimension, les informations « nom de mesure » et « valeur de mesure » présentes dans les données sont « supprimées »
L'augmentation de dimension peut transformer complètement les données, mais les noms de colonnes de dimension peuvent contenir des valeurs nulles ; le remplissage d'informations supplémentaires est donc pris en charge. La réduction de dimension perd du contenu informationnel. Il faut donc conserver des informations de transformation supplémentaires pour atteindre une véritable transformation isomorphe ; sinon, des informations seront forcément perdues.
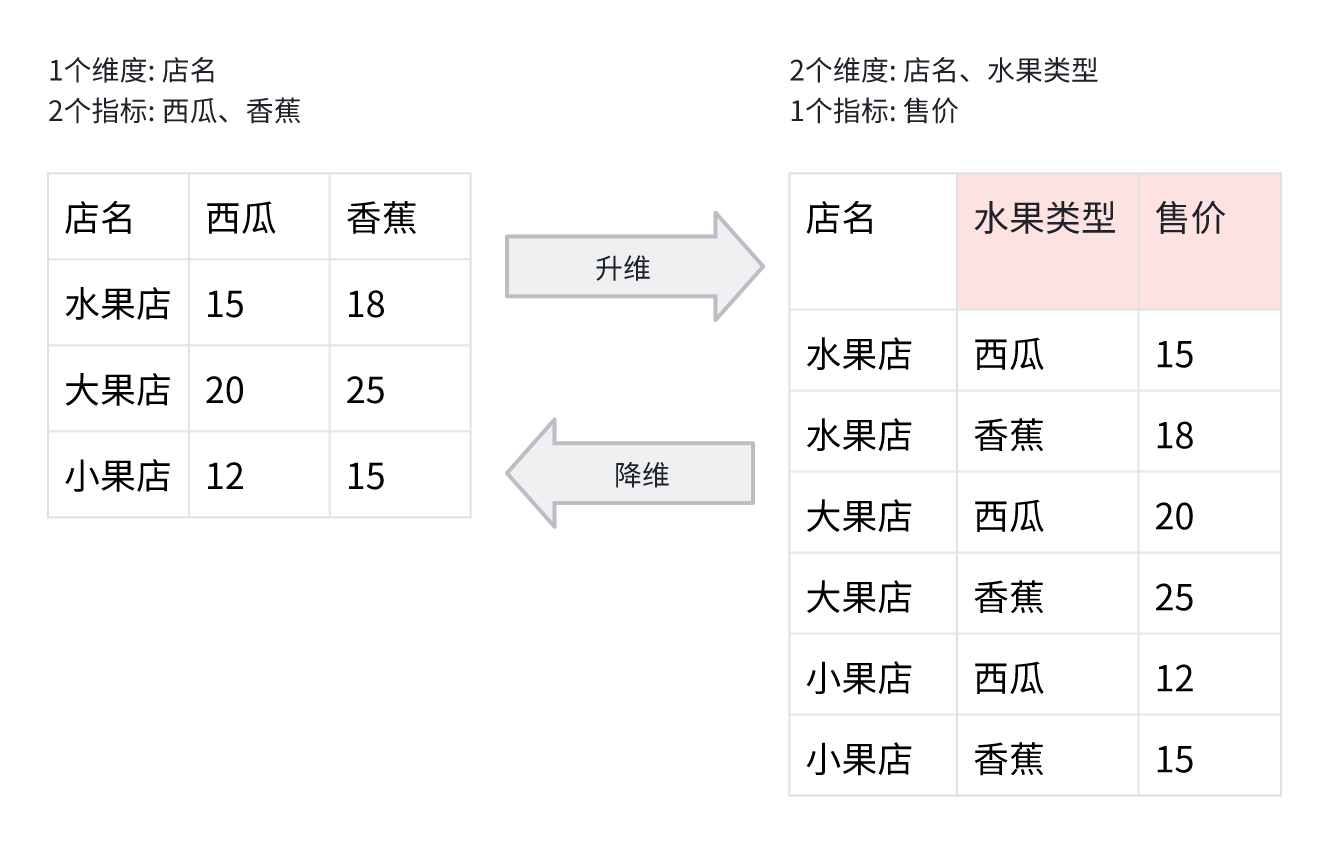
Augmentation et réduction des dimensions groupées
Comme pour l'augmentation et la réduction ordinaires, il existe des scénarios similaires d'ajout ou de perte d'information. De plus, l'introduction du groupement génère davantage de données vides.
Rôle :
- Groupement des mesures : permet de traiter facilement les données de détail via l'augmentation de dimension groupée
- Requêtes multi-groupes : plusieurs SQL peuvent facilement obtenir plusieurs jeux de données de détail, puis les fusionner en un seul jeu via la réduction de dimension groupée

Dérivation des règles
Augmentation de dimension


:::tip
- Pour plusieurs mesures, l'augmentation de dimension ramène le nombre de mesures à 1. Une mesure reste aussi 1 après augmentation.
- Pour plusieurs dimensions, l'augmentation de dimension ajoute une dimension. Même 0 dimension devient 1.
- Avec 0 dimension et 1 mesure, on peut appliquer l'augmentation de dimension à répétition pour obtenir n'importe quel nombre de dimensions et 1 mesure, ce qui permet aussi de tracer un graphique en barres avec une seule mesure. :::
Réduction de dimension

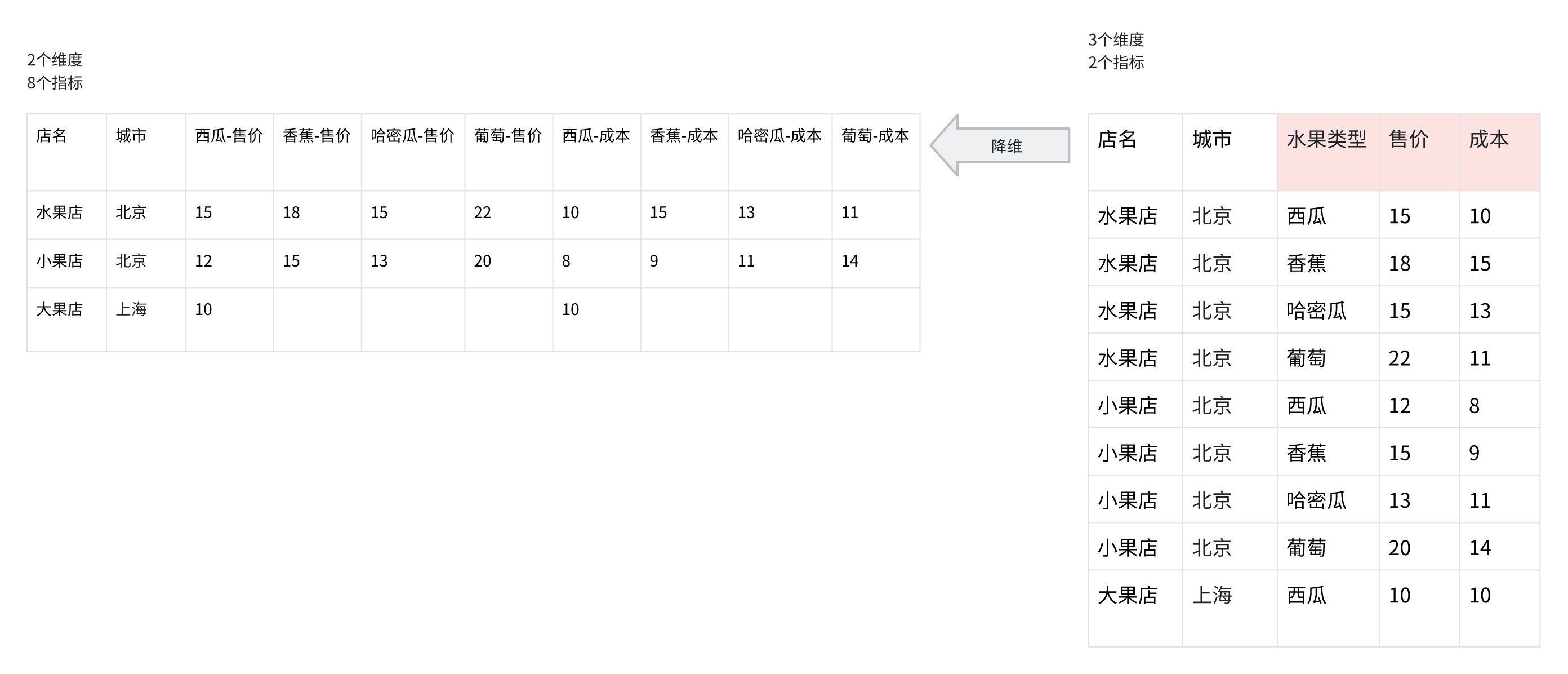
:::tip
- Pour plusieurs mesures, la réduction de dimension fait former un produit cartésien entre les valeurs de dimension et les mesures, créant de nouvelles mesures
- Pour plusieurs dimensions, la réduction de dimension fait former un produit cartésien entre plusieurs valeurs de dimension, créant de nouvelles dimensions :::
Exemples
0 dimension, 1 mesure

0 dimension, 3 mesures

1 dimension, 1 mesure
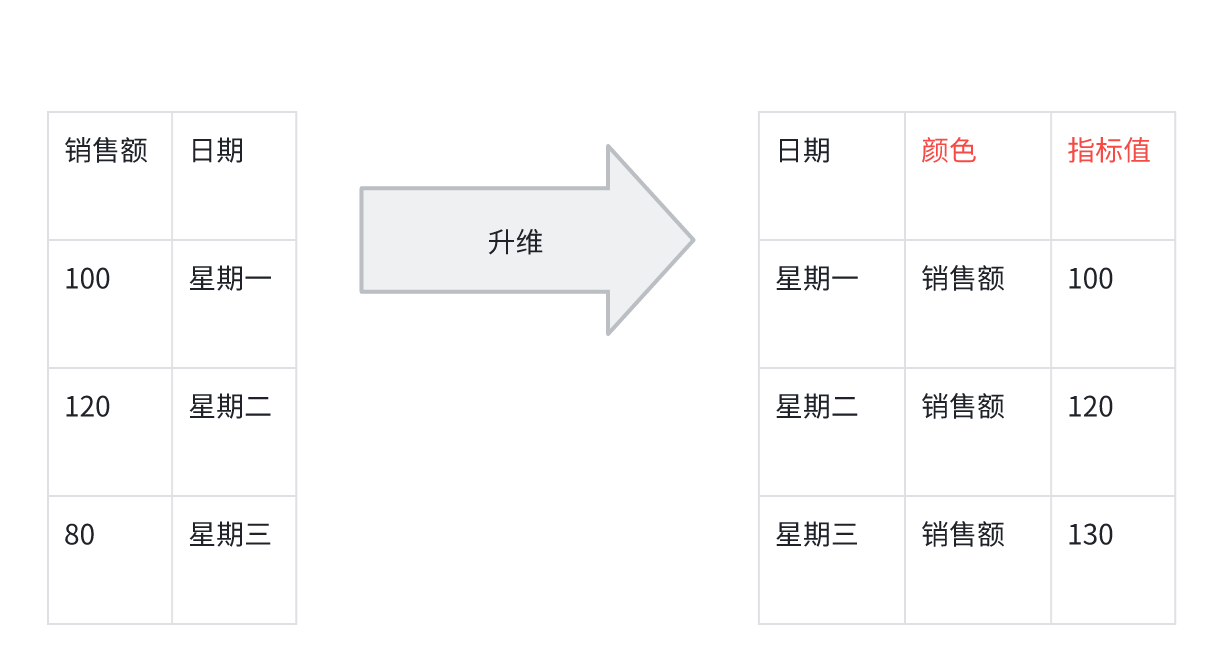
1 dimension, 2 mesures

2 dimensions, 1 mesure

2 dimensions, 2 mesures
