数据重塑-原理
数据重塑
VSeed 提出一种通用的维度重塑方法, 旨在进一步降低数据可视化门槛
数据重塑是指将数据从一种结构化形式转换为另一种结构化形式的过程,核心在于改变数据的组织方式(如行、列、索引、层级),以适应不同的分析或处理需求,同时保持数据的完整性。
维度重塑
Python 和 R 语言有工具已经支持了维度重塑
- Python Pandas 提供了
pivot与melt进行数据重塑 - R tidyverse 提供了
pivot_longer与pivot_wider进行数据重塑
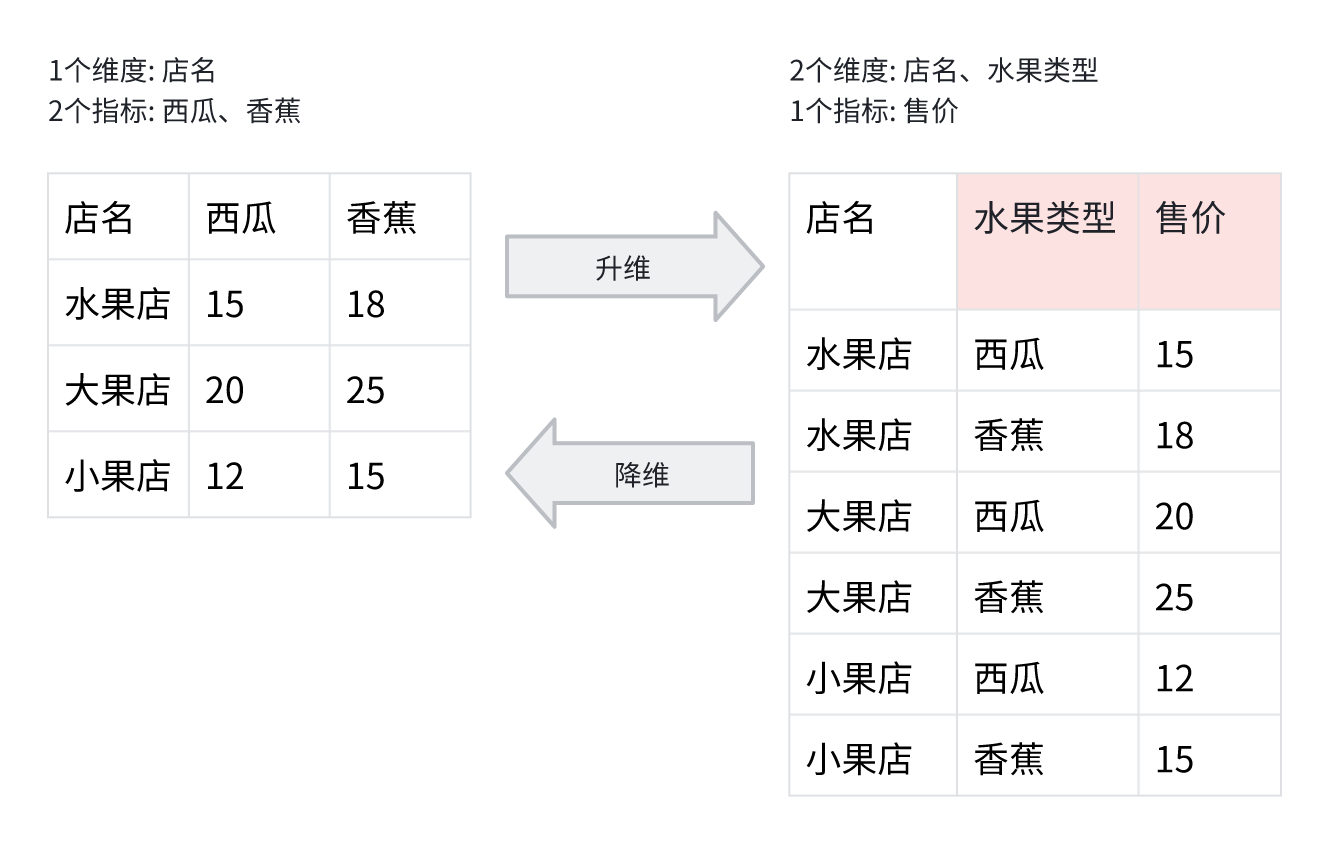
升维与降维
升维、降维在精神上符合范畴论的思想(对象与态射,以及同构),但在实现上并不严格遵循范畴论。 特殊强调:
- 升维时, 会“凭空”创建不存在的“指标名称”与“指标值”信息
- 降维时, 会“移除”数据中存在的“指标名称”与“指标值”信息
升维可以完整的转换数据, 但维度列名称会出现空值, 因此支持填补额外的信息。 降维会丢失信息内容, 因此需要额外的保存转换信息, 才能达到真正意义上的同构转换, 否则信息一定会丢失。
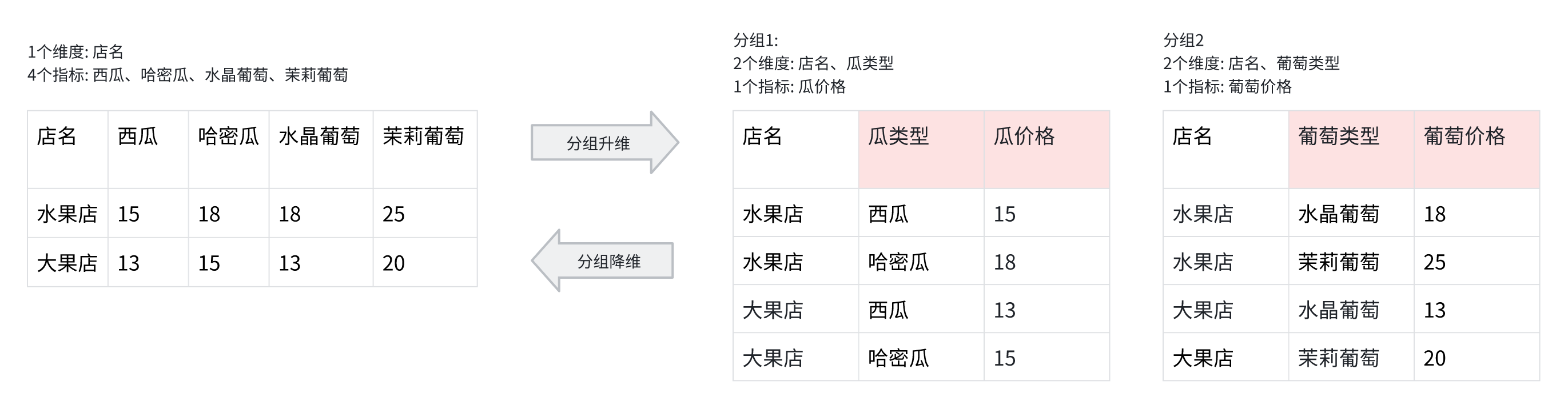
分组升维与降维
同普通的升维和降维, 有类似的信息增加 或 信息丢失场景。 此外由于分组的引入, 会产生更多的空数据 作用意义:
- 指标分组: 以轻松通过分组升维, 快速处理明细数据
- 多组查询: 通过多条 SQL 可以轻松获取到多份明细数据, 它们可以按照分组降维的方式, 合并为一份数据。
规律推导
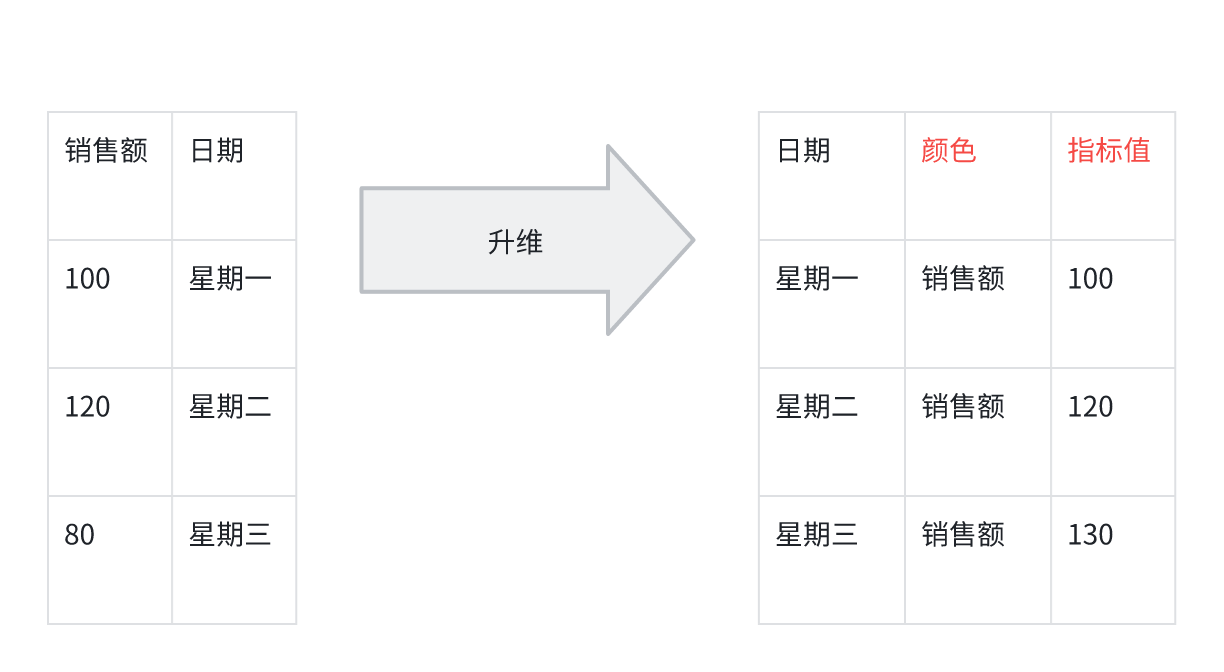
升维


TIP
- 多指标升维, 指标数量变为一, 1 个指标升维后, 指标也还是 1。
- 多维度升维, 维度多一个, 0 个维度也会加 1
- 0 个维度 1 个指标, 可以反复升维, 得到任意个维度和 1 个指标(从而一个指标, 也能画个柱状图)
降维

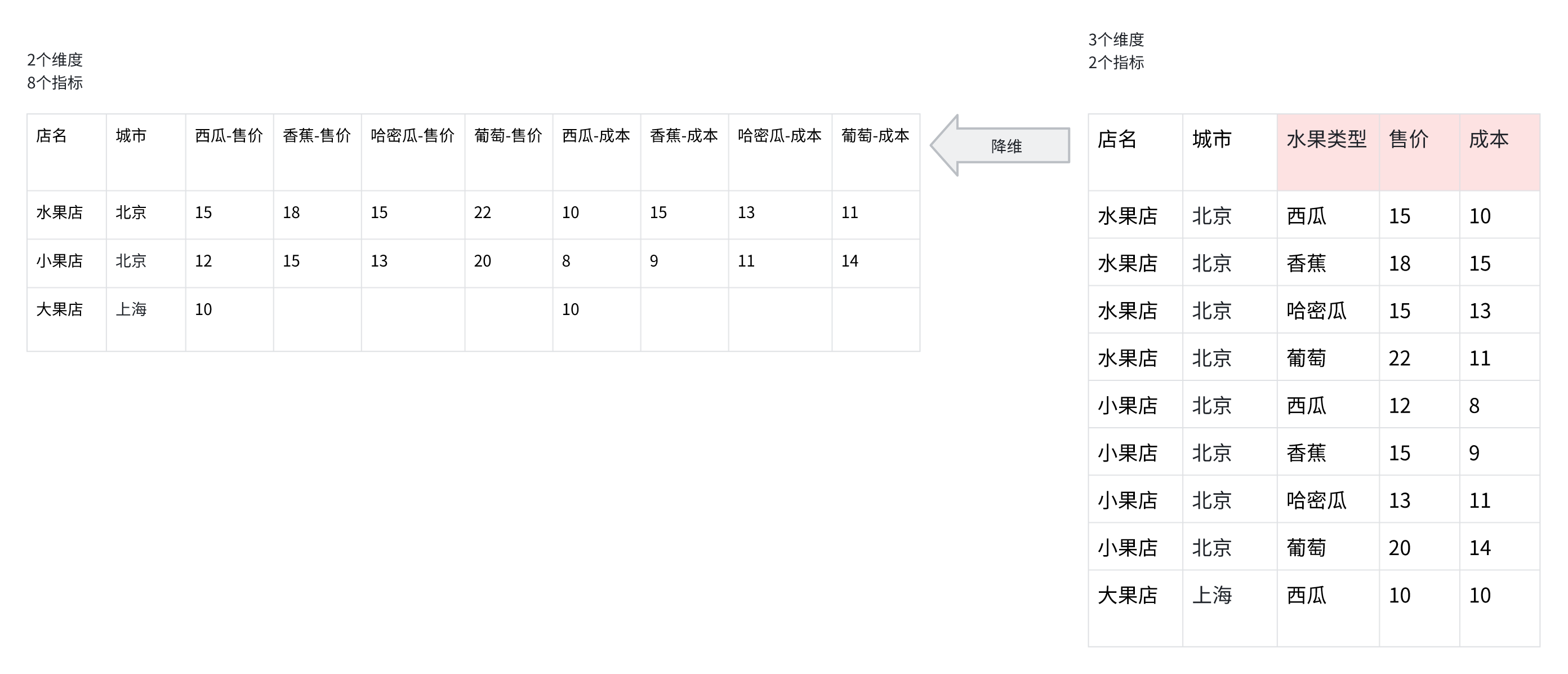
TIP
- 多指标降维, 维值与指标会笛卡尔积, 成为新的指标
- 多维度降维, 多个维度值会笛卡尔积, 成为新的维度
示例
0个维度 1个指标

0个维度 3个指标

1个维度 1个指标
1个维度 2个指标

2个维度 1个指标

2个维度 2个指标

目录